OCR precision,
tailored just for you.
Giving purpose to receipts with AI. Join the revolution of businesses transforming their receipts into powerful digital data.

A fully integrated API to offer OCR receipt scanning and data extraction
Empower Your Business with Taggun
We make it easy for developers to bring to life meaningful projects with receipt OCR. At Taggun, we offer OCR receipt scanning with a personalised edge for greater precision, efficiency, and collaboration. Explore our two innovative Receipt & Invoice OCR products tailored to your needs.
Our clients use our APIs for many different projects such as beating fraud, cashback campaigns, gaining deeper insights into their customers, automating their accounting system, and much more. No matter the scope of your project, our unmatched accuracy and extensive multi-language support ensure you’re always ahead.
What is receipt OCR?
Receipt OCR (Optical Character Recognition) is a software technology that scans images of receipts and digitises the receipt content, including line item information, into structured and meaningful data comprehensible to other software. Commonly extracted data in OCR receipt recognition includes the total amount, tax amount, date, and merchant name of the receipt.
Build with Taggun to offer OCR receipt scanning and data extraction
A super speed machine-only OCR to process your receipts in real-time.
Obsessed about Accuracy
Taggun delivers market-leading accuracy straight out of the box. Our relentless pursuit of accuracy doesn’t stop there – We collaborate with volume and enterprise clients to fine-tune solutions to their specific use cases, achieving unparalleled accuracy that caters to unique business demands.


Expertise that backs your business
Taggun is more than a service provider; we’re your strategic partner. Our proactive approach adapts to evolving regional, linguistic, and compliance needs, ensuring your business continually benefits from a product that grows with you.
“Taggun’s OCR capabilities for the particular receipt use case that Ramp has are better than any other solution that we’ve found on the market. We did look at a few others, the difference is that all the other’s are for general purpose for example, documents and invoices whereas Taggun is excellent at the particular receipt and invoice OCR we require.”
Receipt OCR API features

Global Reach
Multilingual OCR Capability
Streamline your business with our Receipt & Invoice OCR API. With 90%+ accuracy and multi-language support, it seamlessly extracts data from receipts and invoices. Work with us for unparalleled accuracy and recognition of region specific data points. Get buillding today or contact us for a chat.
Multilingual OCR Capability
Streamline your business with our Receipt & Invoice OCR API. With 90%+ accuracy and multi-language support, it seamlessly extracts data from receipts and invoices. Work with us for unparalleled accuracy and recognition of region specific data points. Get buillding today or contact us for a chat.

Continuous Improvement
Agile Flexibility and Personalised Service
Taggun stands apart by offering agility and the ability to grow and adapt with your changing needs, ensuring business continuity without the bureaucratic delays that might be experienced with larger tech companies.
Privacy and Compliance Adherence
Taggun maintains a strong commitment to privacy and compliance, offering customisable privacy measures and server location compliance to align with regional data protection laws, ensuring the business runs without hitches regarding regulatory compliance.
Discover the TAGGUN edge
Processing over 1.5 million scans per month in over 85 languages, and supporting diverse formats and data points.
The easiest OCR receipt API to use

Upload your receipt
Developer friendly RESTful API web services.
TAGGUN APIs accept JPG, PDF, PNG, GIF, and URL of a file.
Get help and code examples here. Too easy
OCR scans receipt to text
Automatically detects the language on the receipt.
Converts image to plain raw text.
Takes advantage of the best OCR engines in the industry.
Configurable to use Google Vision API or Microsoft Cognitive Service API
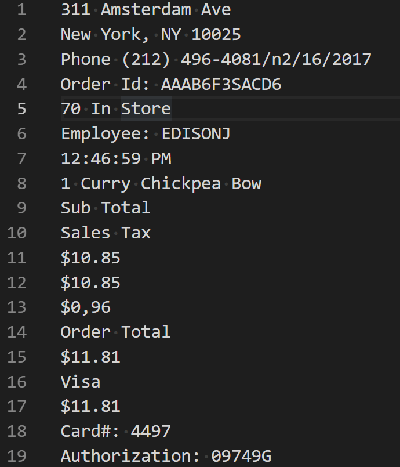

Receipt OCR API results
Taggun's machine learning model classifies keywords on a receipt.
TAGGUN engine extracts key information from raw text.
Calculate the confidence level for each field for accuracy.
Returns detailed information in JSON format.
Results are ready to be consumed by your app.

Try the online demo now
Get a taste of the Taggun Invoice & Receipt OCR.
This demo is just the beginning!
- The API offers many more data points - get your API key here.
- Work with us for over 90% accuracy and optimisation to your business needs.
Optimise an OCR solution for your specific use case.
How businesses are using OCR receipt scanning
Dynamic Solutions for Modern Business

Purchase Validation
Learn how The Arnott’s Group created a direct-to-consumer loyalty campaign using AI receipt scanning and receipt validation.
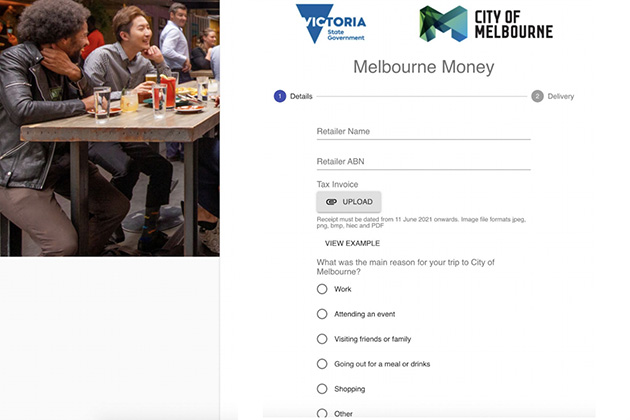
Cashback Campaign
Powered by Taggun’s automatic receipt validation, Waivpay led a $40 million government initiative that offered discounts to dine in Melbourne city.

Finance Administration
By integrating Taggun’s OCR receipt scanning, Ramp was able to streamline repetitive processes, saving financial officers 80% on administrative time
Valuable Use Cases for a Receipt OCR API
Streamline your business with our receipt scanning API. With 90%+ accuracy and multi-language / multi-regional support, it seamlessly extracts data from receipts and invoices. Work with us for unparalleled accuracy and recognition of region specific data points. Get building today or contact us for a chat.
Receipt Data: Extract data from receipts to automate business operations.
Receipt Validation: A Receipt OCR API with validation support validates customer purchases and enables customer engagement and interactive marketing activities, such as rewards, cash-back or loyalty campaigns.
Receipt Fraud Detection: A Receipt OCR API with fraud detection support validates customer receipts as authentic and non-duplicate.
Consumer Insights: Obtain zero-party purchase receipt data, including line item content, from receipts to offer targeted and personalized marketing efforts.
Expense Management: Capture receipt and invoice details to streamline expense tracking processes and generate accurate reports.
Accounting and Bookkeeping: Automate data entry and reduce errors, aiding accounting and bookkeeping tasks.
Move from prototype to production quickly.
We make it super easy for developers to integrate receipt OCR scanning into all websites and apps

Real-time Processing
Deliver a sleek UX without letting users to wait for their receipts and invoices to be processed.
No waiting – It just works
Our API returns the result immediately when you make a request. So, you don’t need a complicated web hook system or poll for results.
Easy with Docs & Code Samples
Integration is a breeze with our comprehensive documentation and code samples.
Always available
Resiliency built in – to make sure your users don’t experience any downtime.
Setting up your Receipt OCR API
Get started today with these developer-friendly links.
Check Out Our API Help Docs
Our API help docs are the perfect guide to effortlessly integrate our solution into your project.
Code examples to get you started
Get starter code examples for node.js, php, C# / .NET, Python and more. With easy-to-follow instructions and comprehensive support, you’ll be up and running in no time.
Register and start building for free
Sign up now for unlimited, free receipt scans for 30 days. Cancel at any time during the trial period via our secure subscription portal. You will not be charged.
Get Started with Taggun
We are excited to build something awesome with you 🚀
Talk with our AI experts about an OCR solution, pricing or if you want support.